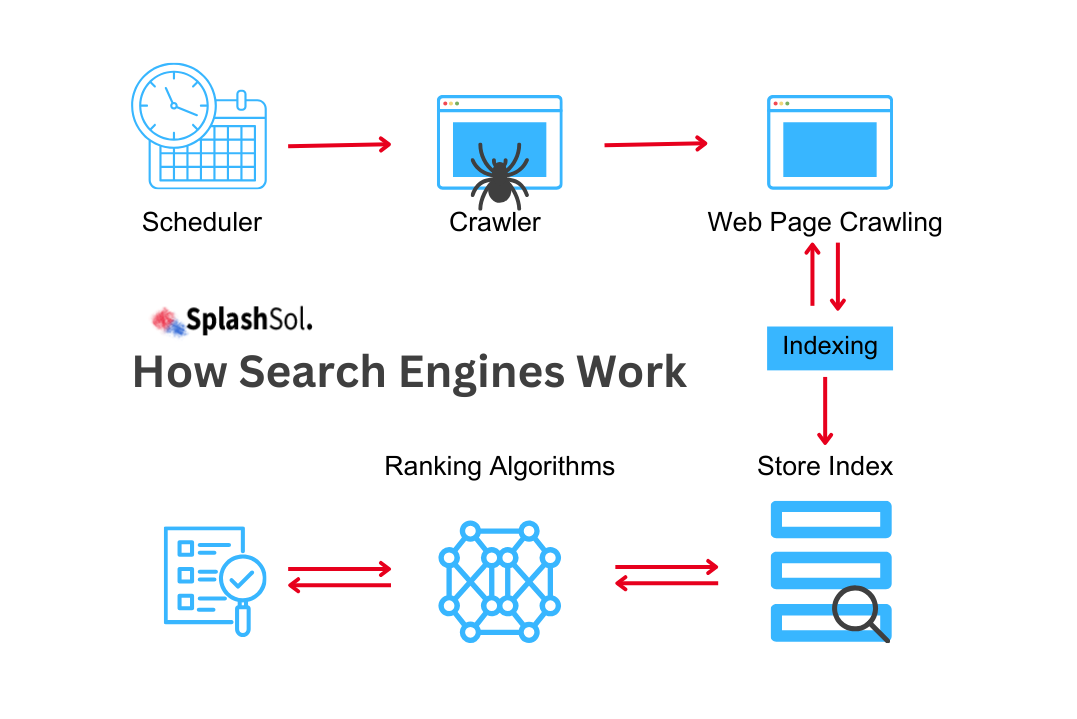
Search engines play a pivotal role in helping users discover relevant information in the vast internet landscape. Behind the scenes, two fundamental processes—crawling and indexing—work together to make this possible.
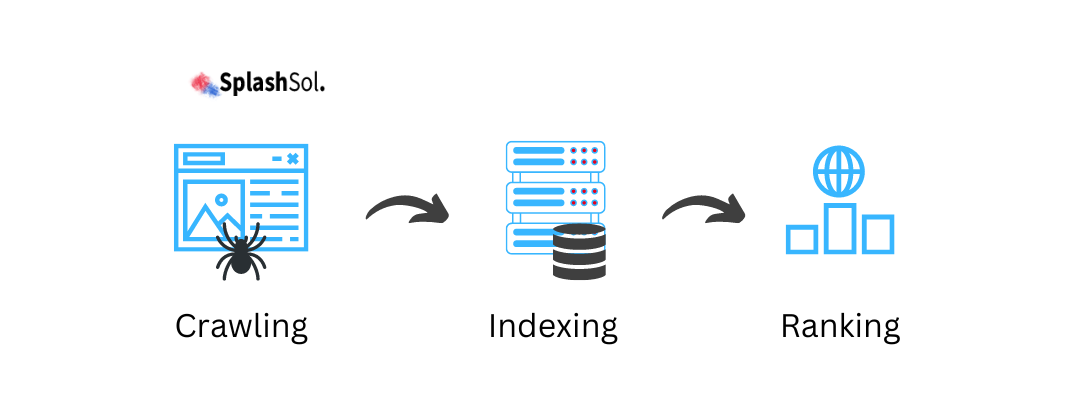
- Crawling: Imagine finding books in a library by walking through the aisles and checking the book spines.
- Indexing: Imagine taking those books, reading them, summarizing their key points, and then filing them on shelves under specific categories and authors.
Definition Of Web Crawling
Web crawling, often referred to as spidering or web spidering, is the automated process through which search engines systematically browse and index content across the vast expanse of the internet.
Imagine an army of virtual bots traversing the web, meticulously visiting websites, and collecting information about their pages. These bots, commonly known as web crawlers or spiders, navigate the complicated network of hyperlinks, discovering and cataloguing data to build a comprehensive index.
- The estimated size of the web is 4.24 billion indexed pages. This number is constantly growing as new content is created and old content is deleted.
- Search engines like Google crawl billions of pages per day. Google alone is estimated to crawl over 20 billion pages per day.
- The average website is crawled about once per month. However, this can vary greatly depending on the website’s popularity and how often it updates its content.
- Search engines are crawling more mobile-friendly websites.
Importance In The Context Of Search Engines
The significance of web crawling in search engines cannot be overstated.
- Foundation for search engine functionality, enabling the creation and maintenance of an extensive index of web content.
- Without web crawling, search engines would lack the vital information needed to deliver users relevant and timely search results.
- The crawling process ensures that search engines are aware of new web pages and updates to existing ones.
- Allows search engines to keep their indexes current, reflecting the ever-changing landscape of online information.
Definition Of Indexing
Web indexing is the process through which the information collected during web crawling is organised, catalogued, and stored in a searchable database.
Once web crawlers have traversed the vast expanse of the internet, collecting data from various websites, the next crucial step is indexing. Think of web indexing as creating a carefully organised library catalogue for the immense volume of web content.
Role In Organising And Storing Information
The role of web indexing extends beyond mere organisation—it is the backbone of how search engines store and retrieve information.
The indexed database serves as a centralised knowledge repository, allowing search engines to respond rapidly to user queries by presenting a ranked list of results based on relevance.
The web index categorises and organises information in a structured manner through sophisticated algorithms.
This organisation is fundamental in ensuring users receive meaningful and contextually relevant results when searching for specific topics or keywords. Without effective indexing, the vast amount of information available on the internet would be akin to an unsorted library, making it nearly impossible for users to find the information they seek in a timely and efficient manner.
The Crawling Process
At the heart of the crawling process are web crawlers, also known as spiders or bots, which are automated programs designed to navigate the vast landscape of the internet.
These digital agents act as the eyes and ears of search engines, systematically traversing the web to discover, analyse, and index web content.
The journey of a web crawler begins with a list of seed URLs or starting points, often provided by the search engine itself.
Web crawlers follow hyperlinks from one web page to another, creating a virtual map of interconnected content. They collect information about each page’s content, structure, and metadata as they move through the web.
The crawling process is dynamic and continuous, with crawlers revisiting pages to ensure the most up-to-date information is captured.
The efficiency and thoroughness of web crawlers directly impact the accuracy and relevance of search engine results.

Functionality of Web Spiders
Web spiders, or bots, function by emulating the behaviour of a human user navigating the web. They send HTTP requests to web servers, mimicking clicking on links and accessing web pages.
Once on a page, the spider parses the HTML code, extracting information such as text content, metadata, and hyperlinks. This information is processed and returned to the search engine’s servers for analysis and storage.
The functionality of web spiders extends beyond merely collecting data. They also play a crucial role in respecting website rules through mechanisms like the “robots.txt” file, which provides instructions to crawlers on which parts of a site should not be crawled.
Additionally, web spiders contribute to discovering new and updated content, ensuring that search engine indexes remain current.
The Indexing Process
The indexing process in search engine optimisation, plays a crucial role in constructing a highly organised and searchable database of web content. Once web crawlers have diligently collected data from across the internet, the indexing process takes centre stage in transforming this raw information into a structured and accessible format.
The collected data is analysed and catalogued during indexing based on various factors, including keywords, metadata, and page relationships.
This organised structure forms the foundation of the search engine’s database, akin to a meticulously curated library catalogue. Each entry in the index contains essential information about a web page, making it possible for the search engine to quickly retrieve and present relevant results in response to user queries.
Enhancing Search Efficiency
The search engine can rapidly sift through the index to identify the most relevant results for a given user query by pre-sorting and categorising vast amounts of data.
Without effective indexing, search engines would need to perform real-time analysis of the entire internet each time a user initiates a search, resulting in significantly slower response times and less accurate results.
The indexed database acts as a roadmap, allowing the search engine to navigate directly to the most relevant information, optimising the user experience and ensuring that search results are delivered promptly.
How Indexing Works
The indexing process involves a sophisticated algorithmic approach that transforms the diverse and unstructured data gathered during web crawling into an organised and accessible format.
The indexing algorithm is the rules and procedures that dictate how this transformation occurs. Here is an overview of how the indexing algorithm works:
| Steps | Description |
| Tokenisation | The algorithm breaks down the content of a web page into smaller units called tokens. These tokens can be words, phrases, or even individual characters. |
| Removal Of Stop Words | Common words like “and,” “the,” and “is” (known as stop words) are often excluded to focus on more meaningful content. |
| Stemming | Words are reduced to their root or base form to ensure that variations of a word are treated as the same entity. For example, “run,” “running,” and “ran” might all be reduced to “run.” |
| Creation Of An Inverted Index | The algorithm generates an inverted index, associating each token with the web pages where it appears. This index allows for rapid retrieval of relevant pages based on user queries. |
| Weighting And Ranking | The algorithm assigns tokens weights based on frequency and relevance. This weighting contributes to ranking search results, ensuring that the most relevant pages appear at the top. |
Factors Influencing The Indexing Process
Several factors influence how the indexing process unfolds, shaping the efficiency and accuracy of the search engine’s database. These factors include:
- Relevance of Content: The algorithm considers the relevance of content, prioritising pages that contain information closely aligned with the user’s query.
- Metadata: Information such as title tags, meta descriptions, and header tags is crucial in understanding the context and relevance of a web page.
- Quality of Backlinks: Inbound links from reputable and authoritative websites can positively influence a page’s ranking in the index.
- Website Structure: The organisation and structure of a website play a role in how efficiently crawlers can navigate and index its content.
- Page Load Speed: Faster-loading pages are often prioritised, contributing to a better user experience and search engine ranking.
Relationship Between Crawling And Indexing
The relationship between crawling and indexing is best described as a seamless and interconnected process that unfolds in tandem to keep search engines updated and relevant.
The journey begins with web crawlers, the digital agents responsible for exploring the vast landscape of the internet. As these crawlers traverse the web, they systematically collect data from web pages, creating a raw repository of information.
Once the crawling phase is complete, the torch is passed to the indexing process. The collected data undergoes a meticulous transformation through the indexing algorithm, which organises, categorises, and structures the information into a searchable database.
The result is an index that acts as a comprehensive roadmap, linking specific words or topics to the web pages where they can be found.
Ensuring Comprehensive Search Results
The seamless integration of crawling and indexing is pivotal for providing users with comprehensive search results. By continuously revisiting and exploring new content, web crawlers ensure that the index remains dynamic and up-to-date.
This real-time updating is crucial for reflecting changes on the web, whether it be the creation of new pages, modifications to existing content, or removing outdated information.
The comprehensive nature of this relationship guarantees that users receive a thorough and diverse set of search results when entering queries. Without effective crawling, the index would lack the richness and depth needed to deliver a broad spectrum of relevant information.
Conversely, without efficient indexing, the wealth of data collected during crawling would be challenging to navigate and present to users in a meaningful way.
Challenges In The Process
Some of the challenges associated with the integration of crawling and indexing include the following.
Handling Duplicate Content
Duplicate content refers to identical or substantially similar information that appears on multiple web pages. Addressing this challenge is crucial because search engines aim to provide users with diverse and relevant search results, and displaying various identical pages would diminish the quality of the results.
Search engines employ algorithms that identify and prioritise the most authoritative or relevant version of the content to tackle duplicate content. This involves analysing factors such as the publication date, page authority, and user engagement metrics.
Additionally, webmasters can use canonical tags to indicate the preferred version of a page, guiding search engines in indexing the correct content.
Successfully managing duplicate content ensures that search results are varied and meaningful, enhancing the overall user experience.
Dealing with Dynamically Generated Pages
Another challenge in the crawling and indexing process arises from dynamically generated pages. Unlike static pages with fixed content, dynamically generated pages are created on the fly based on user interactions, preferences, or other dynamic factors.
This poses a challenge for traditional web crawlers, as the content of these pages may not be readily accessible through standard crawling methods.
Search engines have adapted to this challenge by improving the capabilities of their crawlers to execute JavaScript, which is often used to generate content dynamically. This allows the crawlers to interpret and index content loaded or modified after the initial page load.
Additionally, webmasters can facilitate the indexing of dynamically generated content by providing precise and accessible links, using search engine-friendly URLs, and implementing structured data markup.
Importance For Website Owners
The significance of the crawling and indexing process for website owners is perhaps most evident in its direct impact on search engine rankings.
- Search engines use complex algorithms to determine the relevance and authority of web pages, and how well a site is crawled and indexed plays a crucial role in these evaluations.
- Effective crawled and indexed websites are more likely to have their content accurately analysed and considered for search engine result pages (SERPs).
- It influences the site’s ranking in response to user queries.
- Proper indexing ensures that a website’s content is well-organised, making it easier for search engines to understand the context and relevance of each page.
Best Practices For Optimising Crawling And Indexing
Website owners can employ several best practices to optimise the crawling and indexing of their sites, thereby enhancing their visibility and search engine rankings:
| Create A Sitemap | Providing a comprehensive XML sitemap helps search engine crawlers navigate and understand the structure of your website, ensuring that all necessary pages are discovered. |
| Use Robots.txt | Implementing a well-structured “robots.txt” file allows website owners to guide crawlers on which parts of the site to crawl and which to avoid, preventing sensitive or irrelevant content indexing. |
| Optimise Page Load Speed | Fast-loading pages contribute to a positive user experience and encourage more frequent crawling by search engine bots. |
| Focus On Quality Content | High-quality, relevant, and unique content is more likely to be crawled, indexed, and ranked favourably by search engines. |
| Fix Crawl Errors | Regularly monitor and address any crawl errors reported by search engine tools, as these errors can impact the indexing and ranking of your pages. |
| Mobile-Friendly Design | With the increasing prevalence of mobile users, ensuring your website is mobile-friendly is crucial for user experience and search engine rankings. |
| Monitor Indexation Status | Keep track of the indexation status of your site using webmaster tools to identify any issues and ensure that your important pages are included in the index. |
Webmaster Tools
Webmaster tools are crucial in empowering website owners to take control of the crawling and indexing process, providing valuable insights and controls that can enhance a site’s overall performance.
Here’s how website owners can effectively use these tools:
| Submitting Sitemaps | Webmaster tools allow website owners to submit XML sitemaps, providing search engines with a structured map of the site’s content. This enables more efficient crawling and ensures all necessary pages are discovered and indexed. |
| Robots.txt Management | Through webmaster tools, site owners can review and manage the “robots.txt” file, giving them control over which parts of the site should be crawled and excluded. This is particularly useful for preventing the indexing of sensitive or duplicate content. |
| Crawl Error Reports | Webmaster tools provide detailed SEO reports on crawl errors search engine bots encounter. By regularly monitoring and addressing these errors, website owners can ensure that their site is accessible to crawlers and that potential issues are promptly resolved. |
| Fetch As Google | This feature allows website owners to see their site as Googlebot sees it. It helps identify and troubleshoot any issues hindering proper crawling and indexing. |
Common Issues And Solutions
Indexing and crawling have the following issues.
Crawling Issues
Crawling errors can hinder search engine bots from effectively exploring and indexing a website. Identifying and addressing these errors is crucial for maintaining a healthy online presence. Common crawl errors include:
- 404 Not Found Errors: Occur when a page that was previously accessible is no longer available. The solution involves fixing broken links or redirecting to relevant pages.
- Server Errors (5xx): Indicate issues with the web server. Rectifying server-related problems ensures that search engine bots can access and crawl the site.
- Redirect Chains: Lengthy redirect chains can impact crawl efficiency. Streamlining redirects and ensuring a direct path to the final destination helps prevent crawling issues.
- Blocked Resources: Certain resources, such as JavaScript or CSS files, may be blocked from crawling. Ensuring that critical resources are accessible allows for a more comprehensive crawl.
Improving Crawl Budget
Crawl budget refers to the number of pages a search engine bot will crawl on a website within a given timeframe. Optimising the crawl budget ensures that search engines focus on the most important and relevant pages. Solutions include:
- Prioritising Pages: Use tools like XML sitemaps and proper internal linking to guide search engines toward priority pages, ensuring they are crawled more frequently.
- Reducing Thin Content: Eliminate low-quality or redundant pages that contribute little value, as these pages consume a crawl budget without providing significant content.
- Optimising Server Performance: A fast-loading website allows search engines to crawl more pages within the allocated crawl budget. Improve server performance to enhance crawl efficiency.
Indexing Issues
Indexation problems occur when search engines encounter difficulties in properly including or excluding pages from their index. Addressing these issues is crucial for ensuring the index accurately reflects the website’s content. Common solutions include:
- Robots Meta Tags: Use “noindex” tags strategically to prevent certain pages, such as duplicate content or low-value pages, from being indexed.
- Canonicalisation: Implement canonical tags to specify the preferred version of a page, which is particularly helpful in managing duplicate content issues and consolidating indexing signals.
- XML Sitemaps: Ensure that the XML sitemap accurately reflects the site’s structure and includes priority pages, aiding search engines in efficient indexation.
Solution
To facilitate effective indexing, website owners must ensure their content is accessible and understandable to search engine bots. Solutions include:
- Structured Data Markup: Implement schema.org markup to provide additional context to search engines, helping them understand the content and improve rich snippet displays in search results.
- Mobile-Friendly Design: Optimise the website for mobile devices to enhance accessibility and ensure that search engines can effectively crawl and index mobile content.
- Avoiding Flash or JavaScript-Dependent Content: Ensure critical content is not solely reliant on technologies like Flash or JavaScript, as these may pose challenges for search engine bots.
- Optimising Images and Multimedia: Use descriptive Alt text for images and provide transcripts for multimedia content, enhancing the accessibility of non-text elements for indexing.
Future Trends In Crawling And Indexing
Here is what’s in the future for indexing and crawling.
Impact of AI on Crawling and Indexing
As we look ahead, the integration of artificial intelligence (AI) is poised to revolutionise the traditional approaches to crawling and indexing.
AI-powered algorithms are increasingly adept at understanding context, user intent, and content relevance. Here’s how AI is influencing these processes:
- Content Understanding: AI algorithms can analyse and understand content context more comprehensively, enabling better categorisation and indexing based on semantic understanding rather than relying solely on keyword matching.
- Predictive Indexing: AI can predict user behaviour and trends, allowing search engines to proactively index content that is likely to be relevant in the future. This anticipatory indexing enhances the real-time nature of search results.
- Personalisation: AI-driven personalisation can impact how content is crawled and indexed based on user preferences. Search engines can tailor results to specific users, providing a more personalised and relevant search experience.
Voice Search And Its Implications
The rise of voice search is reshaping how users interact with search engines, and this shift has implications for crawling and indexing:
- Conversational Queries: Voice searches often involve natural language and conversational queries. Search engines must adapt their crawling and indexing processes to understand and respond effectively to these conversational patterns.
- Featured Snippets: Voice search often results in featured snippets, where search engines pull concise answers directly from indexed content. Optimising content to be voice-search-friendly becomes crucial for visibility in these snippet-rich results.
- Local Search Emphasis: Voice searches frequently involve location-based queries. Crawling and indexing algorithms need to prioritise and understand local content, impacting how geographically relevant results are delivered.
Mobile-First Indexing
With the increasing dominance of mobile devices, search engines are shifting towards mobile-first indexing, fundamentally changing how websites are crawled and indexed:
- Mobile Content Priority: Search engines prioritise indexing mobile versions of websites over desktop versions. Website owners must ensure their mobile sites are optimised for crawling and indexing.
- Responsive Design: Mobile-first indexing encourages the use of responsive web design, where a single version of a site adapts to different devices. This simplifies the crawling and indexing process, ensuring consistency across platforms.
Importance Of User Experience In Crawling And Indexing
Search engines are placing greater emphasis on user experience as a ranking factor, impacting how websites are the crawling and indexing rate:
- Page Experience Signals: Factors such as page load speed, mobile-friendliness, and the absence of intrusive interstitials are becoming crucial considerations for search engine ranking. Optimising these aspects enhances both user experience and indexation.
- Core Web Vitals: Metrics like Largest Contentful Paint (LCP), First Input Delay (FID), and Cumulative Layout Shift (CLS) are part of Google’s Core Web Vitals, indicating a focus on delivering a seamless and user-friendly experience. Websites meeting these criteria are likely to be favoured in indexing.
- Structured Data for Rich Results: Implementing structured data markup not only aids search engines in understanding content but also enhances the likelihood of achieving rich results in search, contributing to a more engaging user experience.
Frequently Asked Questions
What is Google crawling and indexing?
Google crawling is the process where Googlebot systematically browses the web to discover and update content.
Indexing involves storing and organizing the information found during crawling so that it can be quickly retrieved for search queries. Together, they enable Google to provide relevant search results to users.
What is Googlebot Google crawler?
Googlebot is Google’s web crawling bot, a software program that systematically browses the internet to discover and update web pages. It collects information about websites, indexes content for Google’s search engine.
Googlebot helps ensure that search results are current and relevant by continuously crawling and updating web page data.
What is crawling indexing and caching in SEO?
In SEO, crawling involves search engine bots systematically browsing the web to discover and update content. Indexing entails storing and organizing this information for quick retrieval.
Caching refers to saving a snapshot of a web page to enhance loading speed. Together, they optimize a site’s visibility and user experience in search results.
Why is Google crawling important?
Google crawling is vital as it allows search engines to discover and index new content on the internet. It ensures that search results are up-to-date and relevant by continuously exploring and updating web pages.
This process is crucial for providing users with accurate and current information when they perform search queries.
How Google works step by step?
- Crawling: Googlebot explores the web to discover new and updated content.
- Indexing: The collected information is organized and stored in the index.
- Ranking: Algorithms evaluate pages to determine their relevance to search queries.
- Results: Relevant pages are displayed in search results based on ranking factors.
What is indexing in SEO?
In SEO, indexing refers to storing and organizing web page information collected by search engine crawlers.
Search engines create an index, a database of web pages and their content, which enables quick retrieval and presentation of relevant results when users make queries on the search engine.

Find Out How SplashSol Can Help Your Business Succeed Online

Your Hub Of Digital Marketing News
Stay Ahead Of The Digital Curve











Take the First Step!
Speak to the Experts - The Top IT Development & Digital Marketing Agency.
Getting in contact with our specialists in simple. All you need to do is fill out the form below and a member of our team will contact you to learn more about your business and goals. We aim to respond to your inquiries within 24 hours.